SingSync
Orchestrating AI-driven vocal separation and real-time lyric synchronization.
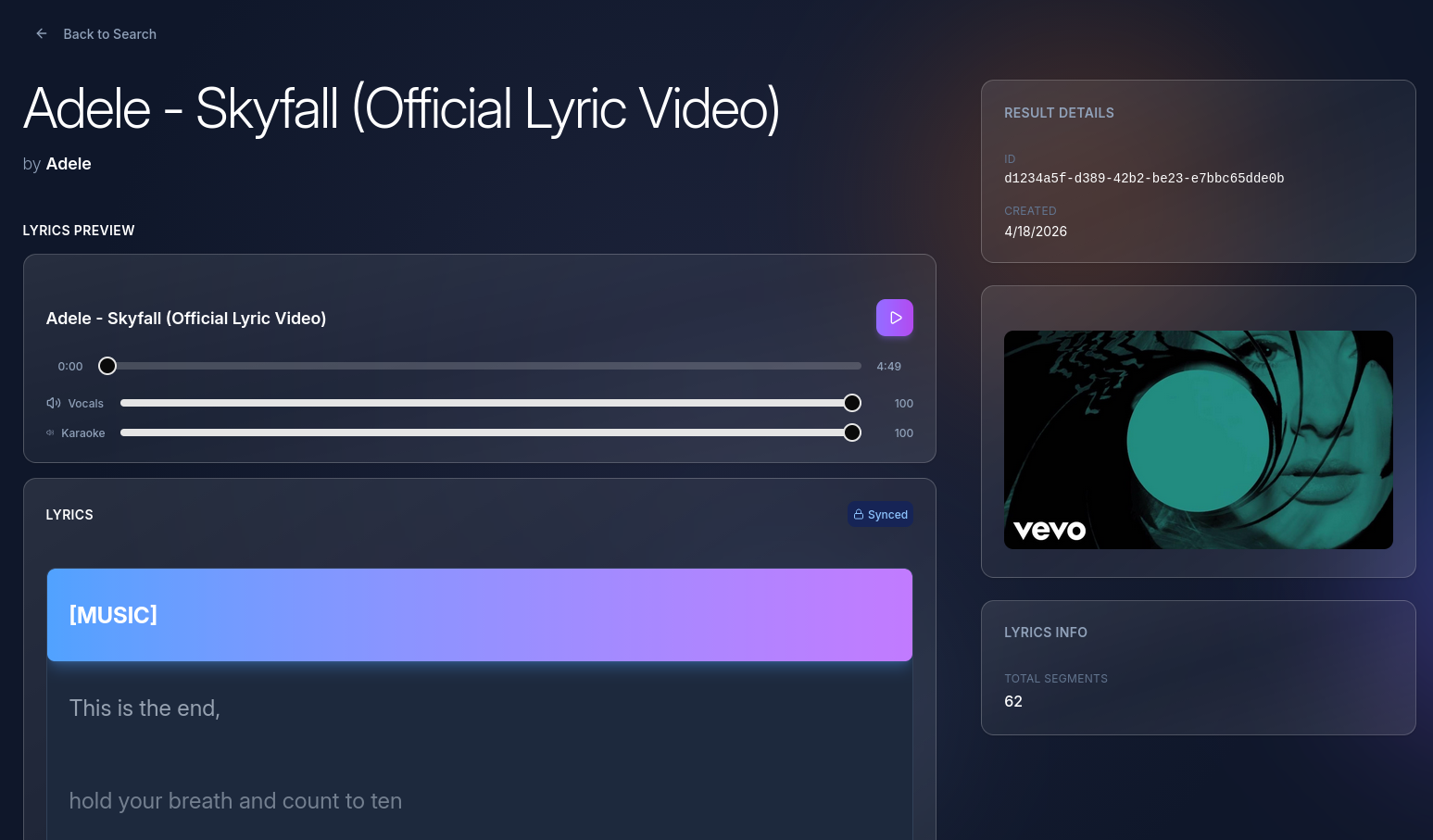
This project was born out of my frustration with trying to find karaoke versions of my favorite songs. I wanted to build a system that could take any track, separate the vocals from the background music, and use AI-driven transcription to sync the lyrics automatically.
I used this as a learning opportunity to explore technologies I hadn't worked with much before. I built the backend in FastAPI, used WebSockets for real-time updates, and managed messaging via Redis Pub/Sub. The entire distributed system is composed of multiple microservices deployed on Kubernetes, and I even threw in Elasticsearch just to see how it would fit into the architecture.
The vocal separation is handled by a pre-trained model called Demucs, which produces surprisingly high-quality results. However, because Demucs is hardware-intensive, I opted for Spleeter in the production deployment; it's much more lightweight, even if the results are a bit lower in quality. For lyric synchronization, I used OpenAI’s Whisper model alongside the stable-ts package to transcribe the vocals and perfectly align them with the original lyrics.
The frontend is a simple React app that provides real-time progress updates, all tied together by an orchestration service that manages the communication between microservices. Overall, it was a rewarding challenge to see everything work together. It’s a great feeling to sing along to perfectly synced tracks—and it makes for a pretty cool party trick. If you want to see it in action, it's currently hosted at https://hatal.cc